
Описание
Para la mayoría de las personas, es difícil obtener la información que necesitan directamente de los datos sin procesar. El aprendizaje automático puede transformar datos desordenados en información útil. Clustering es una técnica de aprendizaje de la máquina sin supervisión que agrupa objetos similares en el mismo cluster. Cluster2A combina los dos algoritmos de agrupamiento más populares, K-means y DBSCAN, para ayudarlo a descubrir patrones interesantes en los datos.
Por ejemplo, Cluster2A puede realizar análisis de clusters en función del comportamiento de consumo del cliente y proporcionar resultados para la segmentación de clientes. La segmentación de clientes es el uso de características específicas para identificar y organizar a los clientes. Estas características pueden ser características demográficas, conductuales / psicológicas y ubicación geográfica. La segmentación de clientes puede identificar a los clientes y proporcionar productos y servicios adaptados a sus necesidades. Esta personalización le proporcionará una ventaja competitiva, aumentará las tasas de conversión de los clientes y la fidelidad a la marca.
Modelo K-means:
El algoritmo de K-menas requiere que se especifique el número de clusters. El objetivo principal es encontrar un punto de datos representativa (lamado centroide) en una gran cantidad de datos de alta dimensión, y luego asignar a cada punto de datos al centroide más cercano.
Modelo DBSCAN:
A diferencia de K-means, DBSCAN no necesita especificar el número de clusters que se generarán. El algoritmo procesa DBSCAN puntos de datos basándose en la densidad, dividiendo principalmente puntos suficientemente densa en el espacio de características en el mismo grupo, y puede identificar los valores atípicos que no pertenecen a ningún grupo, que es muy adecuado para la detección de valores atípicos.
Tipo de datos de crecimiento:
Puede seleccionar datos de series de tiempo con 12 períodos, 24 períodos y 36 períodos para el análisis.
Los datos más comúnmente utilizados son los precios mensuales de material de compra, las ventas mensuales de productos, compras mensuales de clientes, y los ingresos anuales de operación de la empresa.
Por ejemplo, puede realizar un análisis de cluster basado en los datos de compra mensual de los clientes VIP. Cluster2A calculará automáticamente la tasa de crecimiento de compra de cada cliente, la volatilidad de compra y la tasa de crecimiento por unidad de volatilidad, y hará recomendaciones de clustering.
Tipo de datos de característica:
Puede seleccionar de 2 a 10 características para el análisis.
Las características más utilizadas son las siguientes: Demografía: por ejemplo, edad, sexo, ingresos, educación, nacionalidad y tamaño de la familia. Comportamiento / Psicología: por ejemplo, estilo de consumo (modelo RFM) y tipo de personalidad (modelo DISC). Geografía: por ejemplo, país, región y ciudad. Estadísticas / Finanzas: por ejemplo, media, desviación estándar, relación de Sharpe, β, α y R-cuadrado.
Por ejemplo, puede realizar un análisis de clusters basado en las tres características de compra de los clientes, RFM (Recency, Frequency, Monetary).
Скрыть
Показать больше...
Por ejemplo, Cluster2A puede realizar análisis de clusters en función del comportamiento de consumo del cliente y proporcionar resultados para la segmentación de clientes. La segmentación de clientes es el uso de características específicas para identificar y organizar a los clientes. Estas características pueden ser características demográficas, conductuales / psicológicas y ubicación geográfica. La segmentación de clientes puede identificar a los clientes y proporcionar productos y servicios adaptados a sus necesidades. Esta personalización le proporcionará una ventaja competitiva, aumentará las tasas de conversión de los clientes y la fidelidad a la marca.
Modelo K-means:
El algoritmo de K-menas requiere que se especifique el número de clusters. El objetivo principal es encontrar un punto de datos representativa (lamado centroide) en una gran cantidad de datos de alta dimensión, y luego asignar a cada punto de datos al centroide más cercano.
Modelo DBSCAN:
A diferencia de K-means, DBSCAN no necesita especificar el número de clusters que se generarán. El algoritmo procesa DBSCAN puntos de datos basándose en la densidad, dividiendo principalmente puntos suficientemente densa en el espacio de características en el mismo grupo, y puede identificar los valores atípicos que no pertenecen a ningún grupo, que es muy adecuado para la detección de valores atípicos.
Tipo de datos de crecimiento:
Puede seleccionar datos de series de tiempo con 12 períodos, 24 períodos y 36 períodos para el análisis.
Los datos más comúnmente utilizados son los precios mensuales de material de compra, las ventas mensuales de productos, compras mensuales de clientes, y los ingresos anuales de operación de la empresa.
Por ejemplo, puede realizar un análisis de cluster basado en los datos de compra mensual de los clientes VIP. Cluster2A calculará automáticamente la tasa de crecimiento de compra de cada cliente, la volatilidad de compra y la tasa de crecimiento por unidad de volatilidad, y hará recomendaciones de clustering.
Tipo de datos de característica:
Puede seleccionar de 2 a 10 características para el análisis.
Las características más utilizadas son las siguientes: Demografía: por ejemplo, edad, sexo, ingresos, educación, nacionalidad y tamaño de la familia. Comportamiento / Psicología: por ejemplo, estilo de consumo (modelo RFM) y tipo de personalidad (modelo DISC). Geografía: por ejemplo, país, región y ciudad. Estadísticas / Finanzas: por ejemplo, media, desviación estándar, relación de Sharpe, β, α y R-cuadrado.
Por ejemplo, puede realizar un análisis de clusters basado en las tres características de compra de los clientes, RFM (Recency, Frequency, Monetary).
Встроенные покупки
- Modelo DBSCAN
- USD 1.99
- Modelo K-means
- USD 1.99
Скриншоты


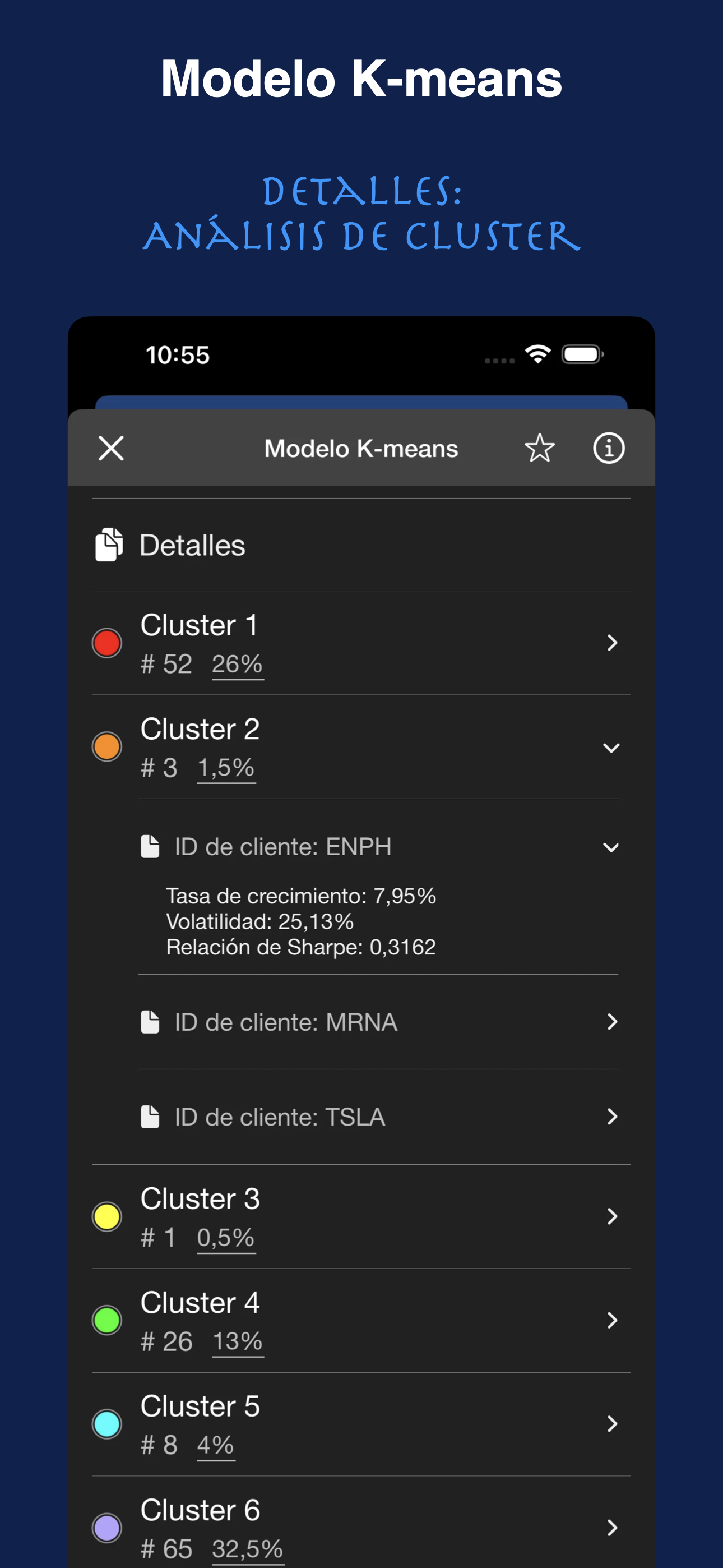





Cluster2A Частые Вопросы
-
Приложение Cluster2A бесплатное?
Да, Cluster2A можно скачать бесплатно, однако в приложении есть встроенные покупки или подписки.
-
Является ли Cluster2A фейковым или мошенническим?
Недостаточно отзывов для надежной оценки. Приложению нужно больше отзывов пользователей.
Спасибо за ваш голос -
Сколько стоит Cluster2A?
Cluster2A имеет несколько покупок/подписок внутри приложения, средняя цена покупки составляет USD 1.99.
-
Сколько зарабатывает Cluster2A?
Чтобы получить оценку дохода приложения Cluster2A и другие данные AppStore, вы можете зарегистрироваться на платформе мобильной аналитики AppTail.

Оценки пользователей
Приложение еще не оценено в Доминиканская Республика.
История оценок
Cluster2A Отзывы Пользователей
Нет отзывов в Доминиканская Республика
Приложение пока не имеет отзывов в Доминиканская Республика.
Оценки
История позиций в топах
История рейтингов пока не доступна
Позиции в категории
Приложение еще не было в топах
Cluster2A Установки
30дн.
Cluster2A Доход
30дн.Cluster2A Доходы и Загрузки
Получите ценные инсайты о производительности Cluster2A с помощью нашей аналитики.
Зарегистрируйтесь сейчас, чтобы получить доступ к статистика загрузок и доходов и многому другому.
Зарегистрируйтесь сейчас, чтобы получить доступ к статистика загрузок и доходов и многому другому.
Информация о приложении
- Категория
- Productivity
- Разработчик
- Chu-Yi Chang
- Языки
- English, French, German, Italian, Japanese, Korean, Russian, Chinese, Spanish, Chinese
- Последнее обновление
- 3.5 (1 год назад )
- Выпущено
- Dec 13, 2020 (4 года назад )
- Также доступно в
- Филиппины , Индия , Италия , Япония , Республика Корея , Кувейт , Казахстан , Ливан , Малайзия , Нигерия , Нидерланды , Норвегия , Непал , Новая Зеландия , Перу , Израиль , Польша , Португалия , Румыния , Россия , Саудовская Аравия , Швеция , Сингапур , Таиланд , Турция , Тайвань , Украина , Соединенные Штаты , Вьетнам , Южно-Африканская Республика , Дания , Аргентина , Австрия , Австралия , Азербайджан , Бельгия , Бруней , Бразилия , Беларусь , Канада , Швейцария , Чили , Китай , Колумбия , Германия , ОАЭ , Доминиканская Республика , Алжир , Эквадор , Эстония , Египет , Испания , Финляндия , Франция , Великобритания , Греция , Гонконг (САР) , Индонезия , Ирландия
- Обновлено
- 1 неделю назад
This page includes copyrighted content from third parties, shared solely for commentary and research in accordance with fair use under applicable copyright laws. All trademarks, including product, service, and company names or logos, remain the property of their respective owners. Their use here falls under nominative fair use as outlined by trademark laws and does not suggest any affiliation with or endorsement by the trademark holders.
AppTail.